I Take two duplicates, eg (I have shifted one of them up 10 or so degrees to make it easier to see):
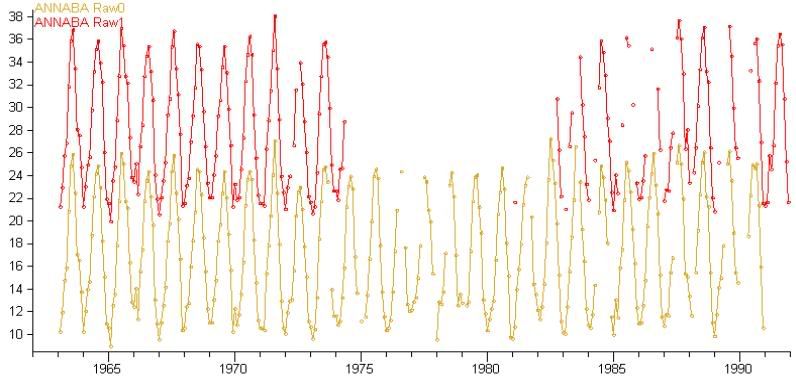
I subtract one duplicate from the other. That produces a list of monthly differences:
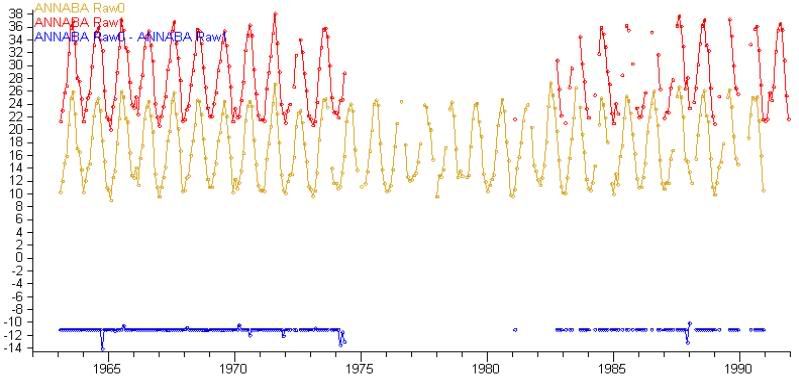
I then get the average of those differences to use as an offset. I use that offset to adjust one of the duplicates to meet the other. I then average the two duplicates to produce a single record (in blue):
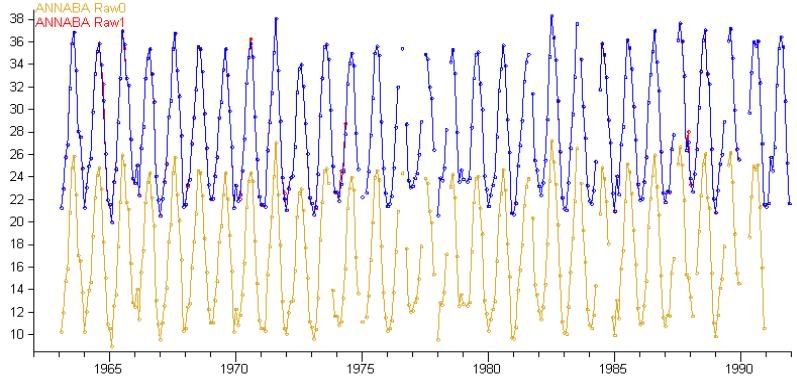
When there are more than two duplicates I continue the process, taking the merged result from the first step and trying to merge a third duplicate with that. During merging if a record contains less than 30 months overlap I abandon the merge and move onto trying to merge the next duplicate record.
I didn't want to lose information by abandoning merges, afterall even though duplicate 0 and 1 might not overlap, they might both overlap well with duplicate 2. So I after the first step above, I go back afterwards to try and merge in any records that failed to be merged in the first time. For example the process to merge 5 records could go like this:
Merge 0+1 pass
Merge (0+1)+2 pass
Merge (0+1+2)+3 fail
Merge (0+1+2)+4 fail
Merge (0+1+2)+5 pass
If I left it at that I would lose both duplicates 3 and 4. But the second go around could now find that duplicate 3 matches:
Merge (0+1+2+5)+3 pass
Merge (0+1+2+5+3)+4 fail
result= (0+1+2+5+3), duplicate 4 discarded.
As a result I only lose one duplicate. I go round and round until no more merges succeed.
Todo
I've only tested this on a handful of stations and by eye it looks okay, but I want to write some validation tests to spot any weird things happening. As it currently stands I calculate an offset when merging two duplicates, but I don't check that the difference between them is roughly a constant offset to begin with. It should be, but it might be possible that a station has two duplicates that totally contradict each other. It would be nice to at least raise a warning for weird stuff like that and review it.
It should be possible to automatically detect a number of other weird things too. For example here's a blog finding a possible problem with a raw GHCN record:
http://kenskingdom.wordpress.com/2010/02/23/cherries-anyone-another-data-“trick”-in-australia/
I haven't looked at it much but it looks like the GHCN raw record duplicate 0 for this station incorrectly contains the tail end of a record that should really be a duplicate in it's own right. As a result the early part of duplicate 0 is offset downward from the latter part - which is separated by a gap.
Here it is in GISTEMP:
http://data.giss.nasa.gov/cgi-bin/gistemp/gistemp_station.py?id=501943800000&data_set=0&num_neighbors=1
If this is an error then my merge method would end up merging the records incorrectly (or rather it wouldn't spot the problem and correct for it). It should be possible to at least identify such a large gap and that the record preceding the gap has a very different average to the record just after it. So that could be flagged as "possible problem".
In this way I could either review the possible problems or run an analysis "with possible problems" and without to see what difference it makes.
Your example is a happy yawn; nothing to worry about there. It's the ones with mismatched and non-overlapping fragments that bother me. A simple flag could just be looking for a calculated offset that's greater than some x.
ReplyDeleteOf course, there are also some cases where you have mismatched fragments even within a single record - possibly due to a station move. Most people deal with that later in a homogenisation step, though I don't see any of the homebrew efforts tackling that yet. How ambitious are you feeling over there?
oh, and are you always starting with record 0? If things are messy, it can matter where you start.
ReplyDelete"It's the ones with mismatched and non-overlapping fragments that bother me"
ReplyDeleteMe too and I want to revisit the method I use to merge duplicates to correct for as much as possible. What I am going to do in the meantime is just do things dead simple to get a global temperature plot and then go back and improve the method later. That can also give an idea of how much the method improvements change the final result.
So at first for homogenization I am just going to average the trends of each merged station record in the gridbox.
"oh, and are you always starting with record 0? If things are messy, it can matter where you start."
yes I saw that I think on Chad's blog? I don't entirely understand why that's the case and my math/stat knowledge is too poor to try and fix it (I kind of understand Tamino's optimal least squares method, but have no idea how to implement such a thing..it's probably not best to follow someone else's method anyway). I will try starting with different records and hope that will show the order doesn't affect the final result much. For example I guess I could start with a random record for the merging and perform the analysis a few dozen times and see what kind of spread of results that produces.
Your approach seems reasonable. Start simple, then revisit, experiment, and see what matters.
ReplyDeleteTamino only used the optimized method when combining different stations, not combining duplicates (which I think you know, just making sure).
Some 'duplicates' look different enough that they could maybe be treated as entirely different stations. Happily this is not the rule.
As for understanding how things work, when combining stations/duplicates that don't overlap or don't align well: I found it's best to just mess around with hypothetical data; things aren't always obvious until you see it in action.